

在Transformer架构主导AI领域八年之后,谷歌正式发布了其继任者——Titans架构。这一全新架构的核心在于将测试时计算应用于记忆层面,旨在解决大型语言模型(LLM)在处理长上下文时遇到的瓶颈。
Titans架构的核心机制:学习测试时记忆
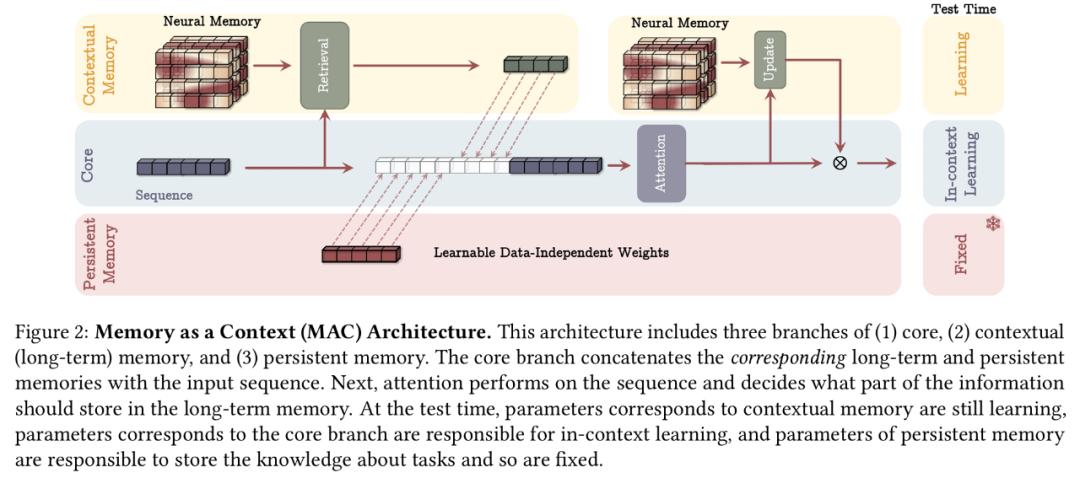
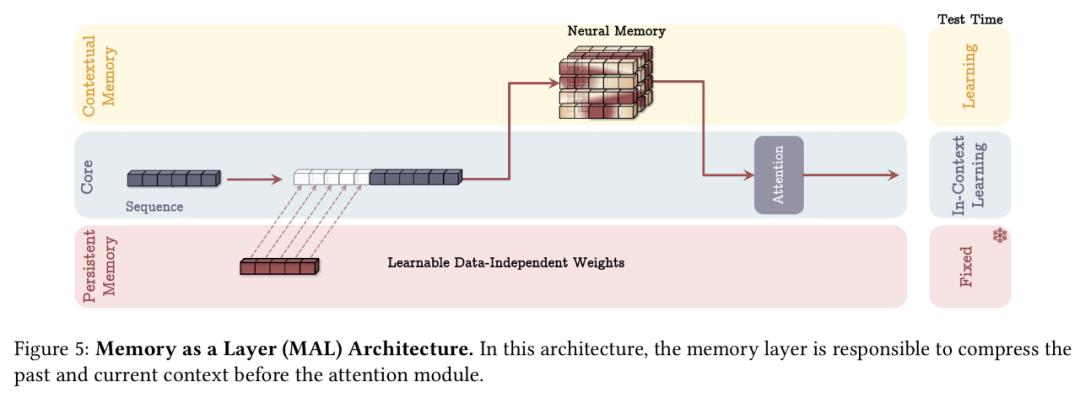
Titans架构的核心在于其长期神经记忆模块,这是一种能够在测试时学习和记忆的元模型。
长期记忆
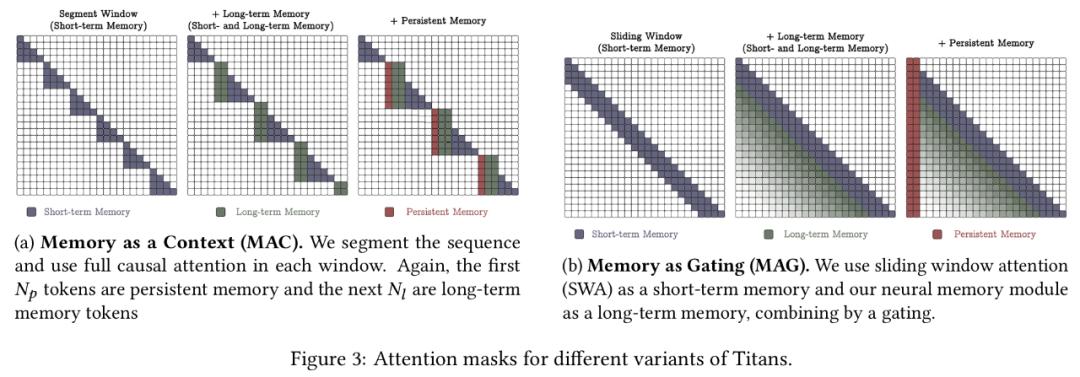
为了实现长期记忆,模型需要将历史信息编码到参数中。传统的神经网络记忆机制存在泛化能力受限、隐私问题等缺陷。因此,谷歌设计了一种在线元模型,使其能在测试时学习记忆或遗忘数据,从而提升泛化性能。
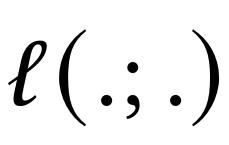
学习过程与意外指标
训练长期记忆的关键是将训练视为在线学习问题。模型需要将过去信息压缩到长期神经记忆模块中。受到人类记忆的启发,谷歌定义了模型的意外程度——即其相对于输入的梯度。梯度越大,表明输入数据与过去数据的偏差越大,因而更值得记忆。基于此,记忆更新规则如下:
M = M + α (S - M)


其中,M表示记忆,S表示意外。

遗忘机制

为处理超长序列,Titans引入了自适应遗忘机制,使得记忆可以遗忘不再需要的信息,有效管理有限的记忆容量。更新规则如下:
M = M - β M

其中,β为遗忘率。

记忆架构
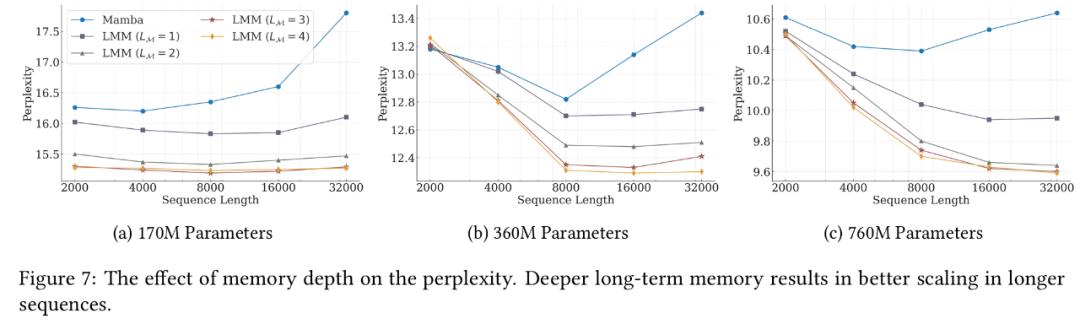
谷歌选择了具有L_M≥1层的简单MLP作为长期记忆架构,希望借此鼓励长期记忆的设计。
Titans架构的应用
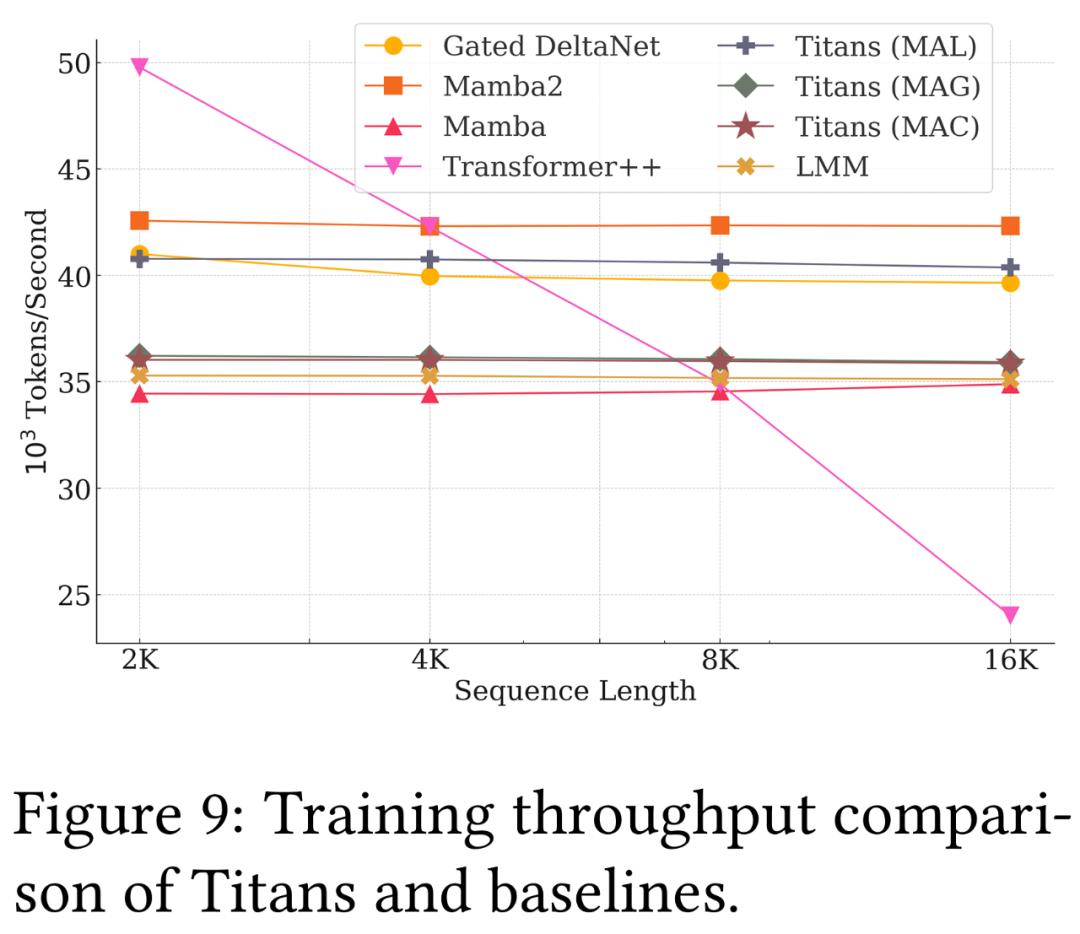
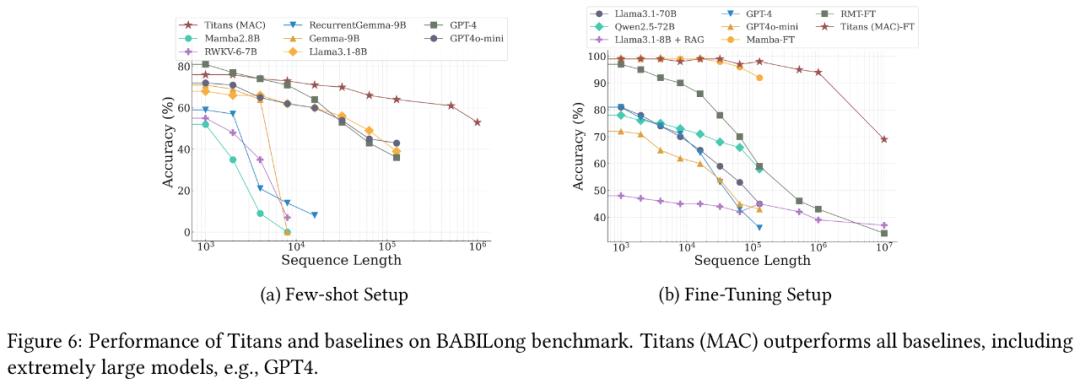
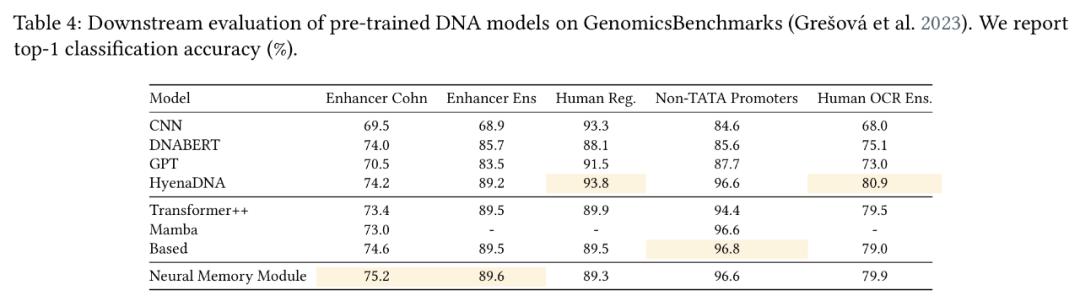
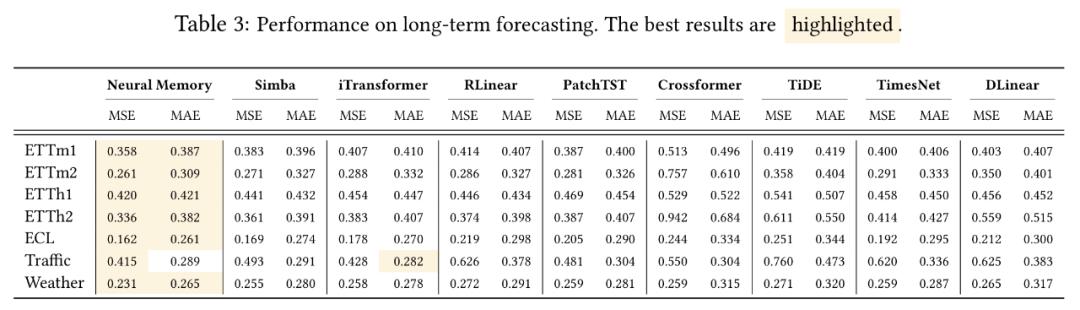
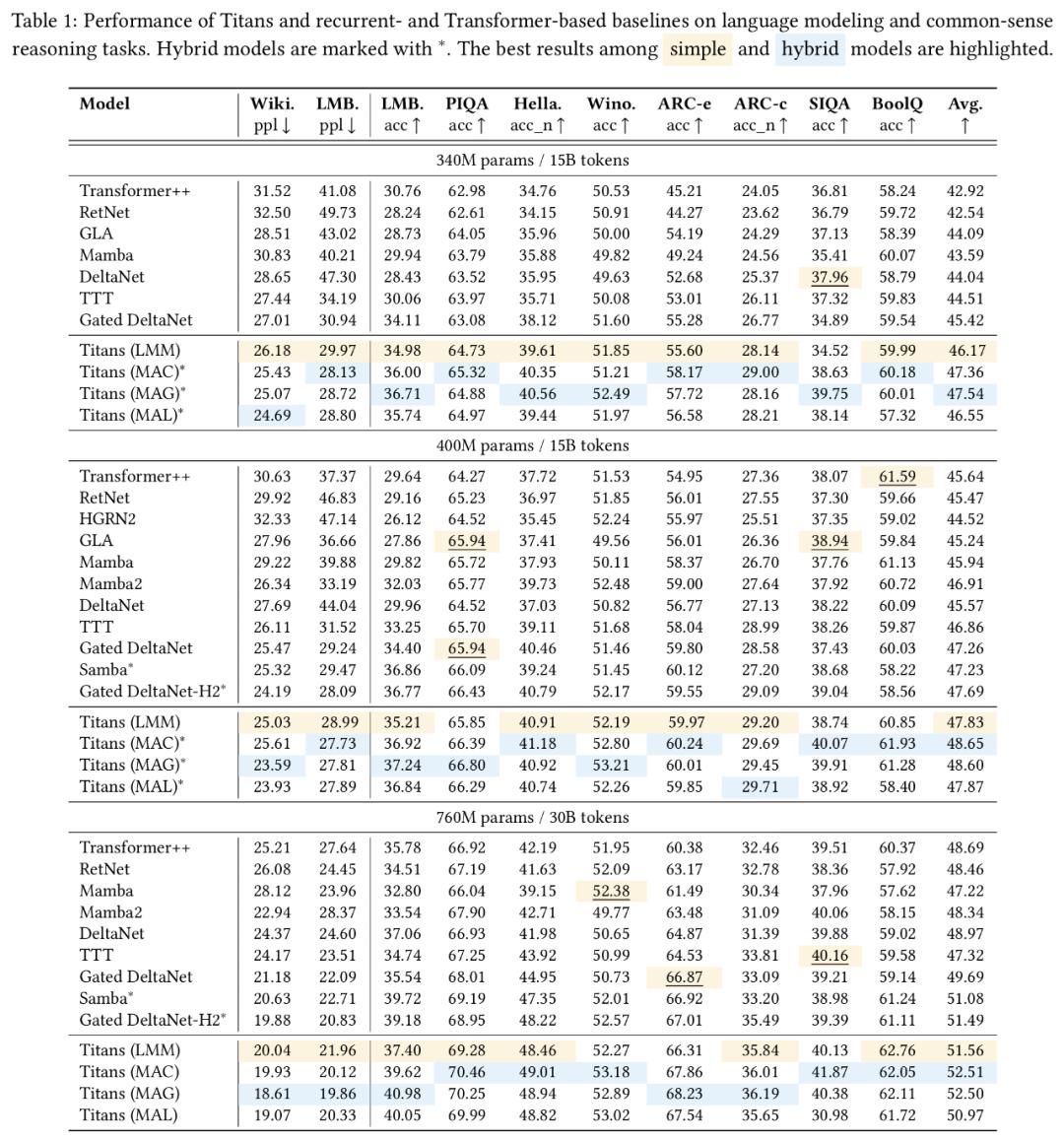
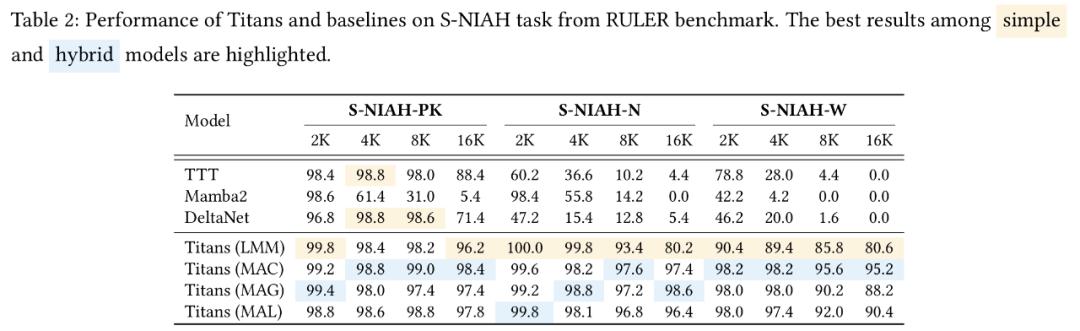
实验结果表明,Titans在语言建模、常识推理、基因组学和时序预测任务中的表现均优于Transformer和现代线性循环模型。尤其在大海捞针测试中,Titans架构能够有效处理超过200万tokens的上下文,且准确性显著高于基准模型。
Titans架构的开源

目前,Titans架构的非官方实现已在GitHub上开源。
GitHub地址:

作者信息

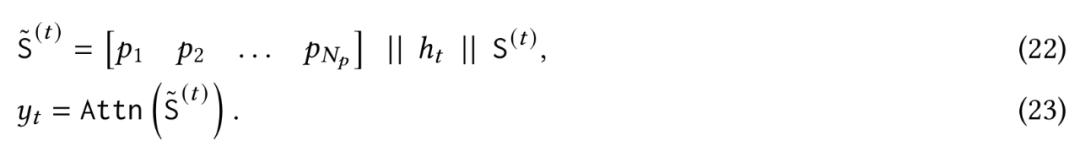


本文作者之一Peilin Zhong毕业于清华姚班,并在哥伦比亚大学获得博士学位,现为谷歌研究科学家。

结论
Titans架构的推出代表着AI领域的一大飞跃。通过将测试时计算应用于记忆层面,Titans解决了LLM在处理长上下文时的瓶颈,为进一步提升LLM的性能提供了新的思路。


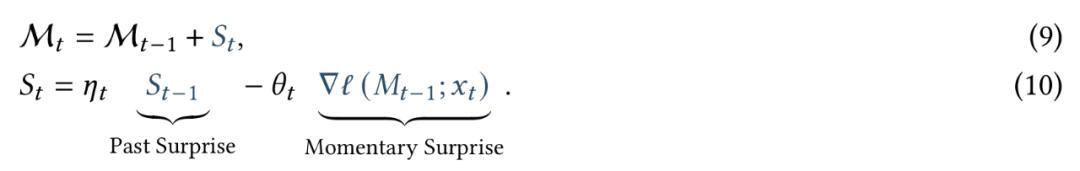

随着Titans架构的开源,相信会有更多研究者参与到这一创新架构的研究中,并推动AI领域的发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...








