
爆火出圈:全球追捧的新宠儿

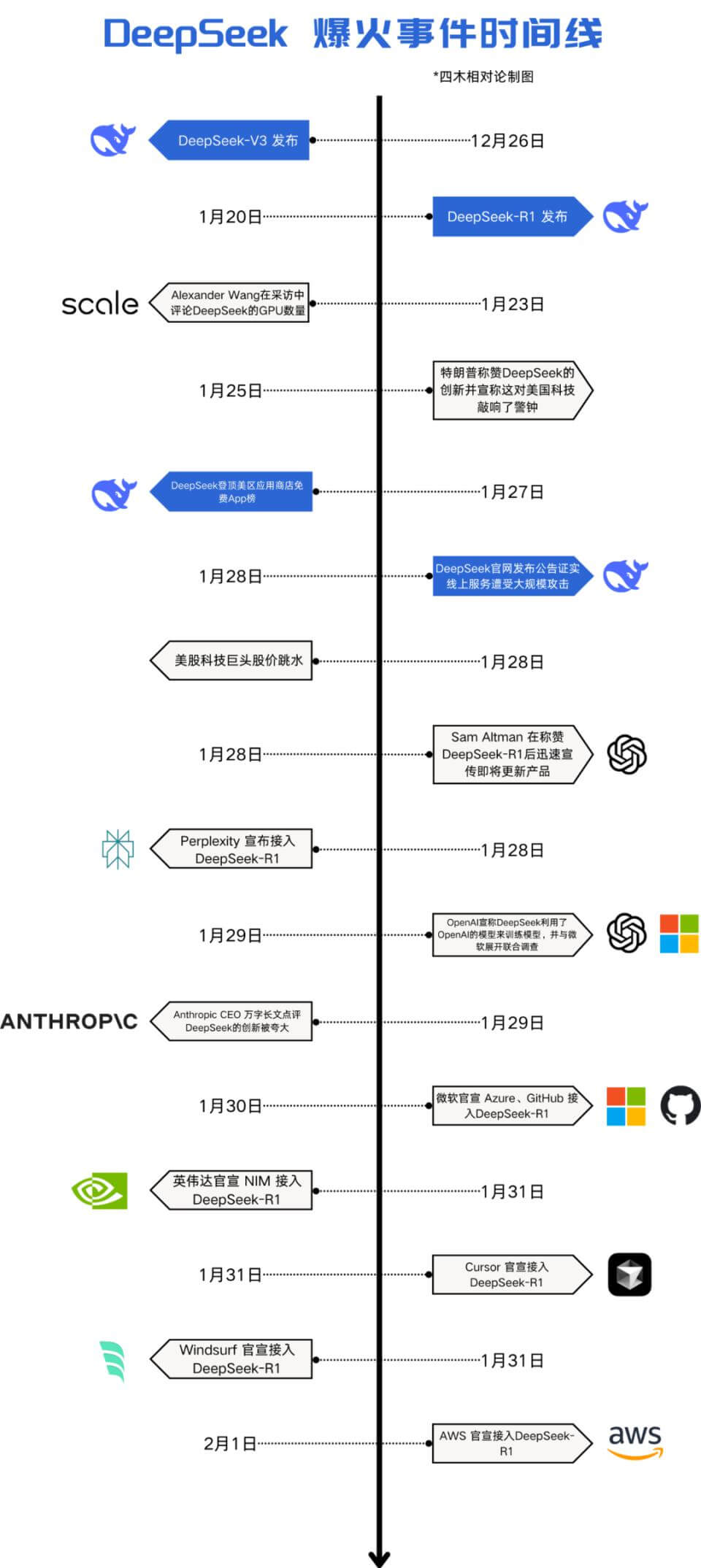
在刚刚过去的春节假期,一款来自中国的 AI 聊天机器人 DeepSeek,犹如一颗横空出世的璀璨新星,在全球范围内掀起了一场前所未有的下载热潮。短短数日,它便以惊人的速度攀升至 140 个国家的苹果 App Store 下载排行榜首位,在美国的 Android Play Store 中同样独占鳌头 。
据市场分析公司 Appfigures 的数据(未包含中国的第三方应用商店),DeepSeek 的应用程序于 1 月 26 日首次登上苹果 App Store 的榜首,并持续稳坐全球领先的宝座。其中,印度成为了新用户增长的最大来源地,贡献了所有平台下载量的 15.6%。Sensor Tower 的研究进一步显示,DeepSeek 自 1 月 28 日起便稳居美国 Android Play Store 的榜首。发布后的前 18 天内,DeepSeek 就实现了 1600 万次的下载,几乎是竞争对手 OpenAI 的 ChatGPT 同期下载量的两倍。
不仅如此,QuestMobile 数据显示,DeepSeek 在 1 月 28 日的日活跃用户数首次超越豆包,随后在 2 月 1 日突破 3000 万大关,成为史上最快达成这一里程碑的应用。据 AI 产品榜,今年 1 月 20 日 DeepSeek-R1 模型发布后,1 月 DeepSeek 用户增长达 1.25 亿。其中,80% 以上用户来自 1 月最后一周,即DeepSeek 在没有任何广告投放情况下实现了 7 天完成 1 亿用户增长。大量用户的接入,令 DeepSeek 此前因访问量剧增而多次出现了宕机现象。
这一现象级的爆火速度,不仅让 DeepSeek 在短时间内积累了海量的用户群体,更是吸引了全球目光聚焦,成为了人工智能领域当之无愧的焦点。是什么让 DeepSeek 在高手如云的 AI 领域中脱颖而出,创造如此辉煌的成绩?接下来,让我们一同深入探寻它的独特魅力。
前世今生:成长历程回顾
DeepSeek 的诞生,可谓是含着 “金汤匙”。它于 2023 年 7 月 17 日正式成立,背后的创立者是知名量化资管巨头幻方量化 。幻方量化在量化投资领域的深厚积累和强大实力,为 DeepSeek 提供了坚实的资金和技术支持,使其从一开始就站在了巨人的肩膀上。
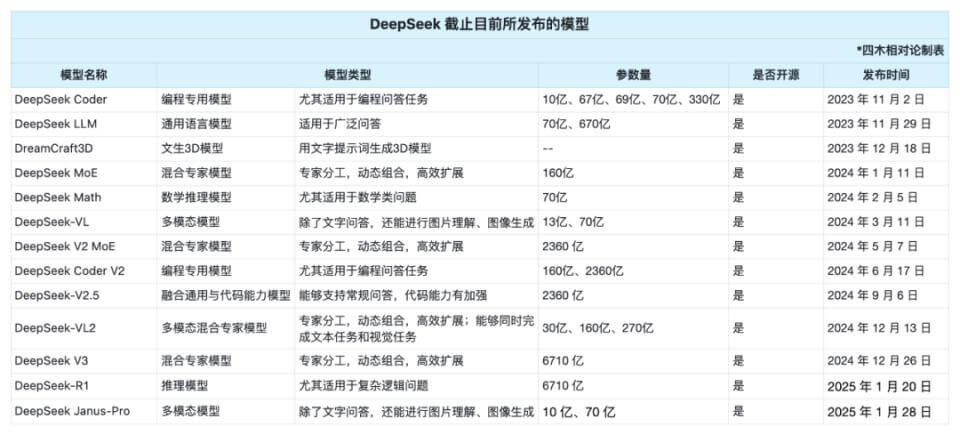
自成立以来,DeepSeek 便开启了一段飞速发展的征程。2023 年 11 月 2 日,它发布了首个开源代码大模型 DeepSeek Coder,这一模型犹如一颗投入湖面的石子,在人工智能领域激起了层层涟漪。它支持多种编程语言的代码生成、调试和数据分析任务,为开发者们提供了强大的工具,帮助他们更高效地完成代码相关工作。
仅仅 27 天后,即 2023 年 11 月 29 日,DeepSeek 再次发力,推出了参数规模达 670 亿的通用大模型 DeepSeek LLM,包括 7B 和 67B 的 base 及 chat 版本。这一模型的诞生,标志着 DeepSeek 在大语言模型领域迈出了重要的一步。它从零开始在一个包含 2 万亿 token 的数据集上进行训练,数据集涵盖中英文,丰富的数据使得模型具备了更强大的语言理解和生成能力。
进入 2024 年,DeepSeek 的发展速度依旧迅猛。5 月 7 日,第二代开源混合专家(MoE)模型 DeepSeek-V2 震撼发布,其总参数达 2360 亿,推理成本却降至每百万 token 仅 1 元人民币。这一模型在性能上比肩 GPT-4Turbo,价格却只有 GPT-4 的仅百分之一,“AI 届拼多多” 的名号由此而来。它的出现,打破了人们对大模型性能与价格的传统认知,让更多人能够以较低的成本享受到强大的人工智能服务。
2024 年 12 月 26 日,DeepSeek 又一次给世界带来惊喜,发布了 DeepSeek-V3。这一模型总参数达 6710 亿,采用创新的 MoE 架构和 FP8 混合精度训练,训练成本仅为 557.6 万美元。在聊天机器人竞技场(Chatbot Arena)上,DeepSeek-V3 排名第七,在开源模型中独占鳌头,成为全球前十中性价比最高的模型。它的创新技术和出色表现,进一步巩固了 DeepSeek 在人工智能领域的地位。
时间来到 2025 年,1 月 20 日,新一代推理模型 DeepSeek-R1 正式发布,这无疑是 DeepSeek 发展历程中的又一个高光时刻。该模型在数学、代码、自然语言推理等任务上,性能与 OpenAI 的 o1 正式版持平,并同步开源。1 月 24 日,在国外大模型排名 Arena 上,DeepSeek-R1 基准测试升至全类别大模型第三,其中在风格控制类模型(StyleCtrl)分类中与 OpenAI o1 并列第一,其竞技场得分达到 1357 分,略超 OpenAI o1 的 1352 分。这一成绩的取得,让 DeepSeek-R1 在全球范围内备受瞩目,吸引了大量用户和开发者的关注。
从最初的蹒跚学步到如今的大步跨越,DeepSeek 在短短一年多的时间里,凭借着不断的技术创新和突破,发布了多个具有里程碑意义的模型,逐渐在竞争激烈的人工智能领域崭露头角,成为了全球人工智能领域不可忽视的力量。
核心优势:技术能力剖析
(一)强大的模型性能
DeepSeek 的模型在自然语言处理、数学、代码等多个领域都展现出了令人瞩目的实力。在自然语言处理任务中,它能够准确理解用户的意图,生成流畅、自然且富有逻辑的回答。无论是日常对话、文本创作还是阅读理解,DeepSeek 都能应对自如,为用户提供高质量的交互体验。
在数学领域,DeepSeek 的表现同样出色。以美国数学邀请赛(AIME)2024 的测试为例,DeepSeek-R1 在该测试中取得了优异的成绩,超越了 OpenAI 的 o1 模型。这一结果充分证明了它在复杂数学问题求解上的卓越能力,能够帮助学生、科研人员等解决各种数学难题。
在代码生成和编程辅助方面,DeepSeek 也展现出了强大的实力。它支持多种编程语言,能够根据用户的需求快速生成高质量的代码。无论是函数编写、算法实现还是程序调试,DeepSeek 都能提供有效的帮助,大大提高了开发者的工作效率。
与其他知名模型相比,DeepSeek-R1 在多项基准测试中都能与 OpenAI 的 o1 模型表现持平甚至超越。在创意写作方面,DeepSeek-R1 能够生成更具创意和想象力的内容,为用户带来更多的惊喜。在推理任务中,它对细节的处理更加精准,能够给出更全面、深入的分析。
(二)创新的技术架构
DeepSeek 采用了一系列创新的技术架构,其中混合专家架构(MoE)尤为引人注目。MoE 架构通过动态选择专家网络,实现了计算资源的优化利用和模型性能的提升 。在处理不同的任务时,MoE 架构能够根据输入数据的特点,自动选择最合适的专家网络进行处理,就像一个经验丰富的指挥官,能够根据战场形势灵活调配兵力。
以 DeepSeek-V3 为例,它采用了 MoE 架构,并引入了无辅助损失策略,有效解决了传统 MoE 模型中专家负载不平衡的问题。在大规模训练场景下,这种架构使得模型能够更加灵活地应对各种复杂任务,显著提升了模型的性能和效率。与传统的单一模型架构相比,MoE 架构就像是一个由多个专业选手组成的团队,每个选手都在自己擅长的领域发挥优势,从而使整个团队在各种任务中都能表现出色。
此外,DeepSeek 还引入了多头潜在注意力(MLA)机制。通过低秩压缩,MLA 机制减少了 KV 缓存的存储需求,同时保持了与标准多头注意力相当的性能。这一创新使得 DeepSeek 在长序列任务中的推理性能得到了显著优化,能够更高效地处理大规模文本数据。
(三)亲民的成本优势
在训练成本方面,DeepSeek 展现出了巨大的优势。以 DeepSeek-V3 为例,其训练成本仅为 557.6 万美元,而同样是开源模型的 Meta 旗下 Llama3.1 405B 模型的训练成本超过 6000 万美元,OpenAI 的 GPT-4o 模型的训练成本更是高达 1 亿美元。DeepSeek-V3 在训练时使用的是算力受到限制的英伟达 H800 GPU 集群,却能在如此低的成本下完成训练,这得益于其创新的技术架构和高效的训练算法。
在使用成本上,DeepSeek 同样具有吸引力。其 API 服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16 元,而 OpenAI o1 模型上述三项服务的定价分别为 55 元、110 元、438 元。如此低的使用成本,使得更多的企业和个人能够负担得起,为人工智能的普及和应用提供了更广阔的空间。
DeepSeek 的成本优势,就像一把利剑,打破了传统人工智能开发中 “高成本、高门槛” 的壁垒。它使得更多的企业和开发者能够参与到人工智能的创新和应用中来,推动了整个行业的发展和进步。对于那些预算有限但又渴望利用人工智能技术提升业务效率的中小企业来说,DeepSeek 无疑是一个理想的选择。
应用落地:多领域开花
DeepSeek 的强大能力,使其在金融、医疗、教育、汽车等多个领域都得到了广泛的应用,为各行业的发展带来了新的机遇和变革。
在金融领域,多家金融机构已经开始接入 DeepSeek。国金证券完成了 DeepSeek 本地化部署测试,将其融入信息检索、文档处理、行业研究及市场研判等多个核心业务领域 。华福证券成功接入 DeepSeek V3 和 R1 两款大模型产品,赋能员工知识问答、辅助软件研发、辅助制定营销方案、增强客户陪伴等业务场景。江苏银行依托 “智慧小苏” 大语言模型服务平台,本地化部署微调 DeepSeek-VL2 多模态模型、轻量 DeepSeek-R1 推理模型,分别运用于智能合同质检和自动化估值对账场景中,通过对海量金融数据的挖掘与分析,重塑金融服务模式。这些应用不仅提高了金融机构的工作效率,还为客户提供了更精准、个性化的金融服务。
医疗领域同样是 DeepSeek 的重要应用场景。智云健康将 DeepSeek-R1 模型接入公司自研医疗人工智能系统 “智云大脑”,增强了数据挖掘能力,提高了数字化慢病管理效率。鹰瞳 Airdoc 自主研发的万语医疗大模型完成焕新升级,接入 DeepSeek R1 模型,实现了临床诊断效率和准确率的双突破、更专业的报告解读、更个性化的健康管理体验升级。深圳大学附属华南医院率先通过本地化部署国产人工智能大模型 DeepSeek-R1,开启 “AI 医院” 建设新篇章,探索 AI 智能体在医学知识库和智能问答、临床辅助诊断、健康宣教、流程优化、数据驱动决策等场景的创新应用。DeepSeek 在医疗领域的应用,为医疗诊断、健康管理等提供了更智能、高效的解决方案,有助于提升医疗服务的质量和水平。
在教育领域,网易有道宣布 “全面拥抱 DeepSeek-R1”。旗下 AI 全科学习助手 “有道小 P” 结合 DeepSeek-R1 超长思维链所提供的思考及分析能力,实现了对个性化答疑的进一步升级。Hi Echo、有道智云、QAnything 等产品也全面接入 DeepSeek 推理能力,并陆续升级;融合全新推理大模型能力的智能硬件新品及 “有道小 P” 2.0 版本也已推出。某中学使用 DeepSeek 进行作业批改,教师的工作效率提高了 50%,学情分析报告为教师调整教学策略提供了有力依据,班级学生的平均成绩在学期末提升了 8 分。DeepSeek 在教育领域的应用,为学生提供了更个性化的学习支持,帮助教师提高了教学效率和质量,推动了教育的智能化发展。
汽车行业也掀起了与 DeepSeek 融合的热潮。吉利汽车将 DeepSeek-R1 模型与自研的星睿车控 FunctionCall 大模型、汽车主动交互端侧大模型等进行蒸馏训练,融合后的 AI 系统能精准理解用户意图,调用车载接口,基于场景主动分析用户需求,提供车辆控制、主动对话、售后等服务,大幅提升智能交互体验。极氪宣布其智能座舱团队已完成旗下自研 Kr AI 大模型与 DeepSeek R1 大模型的深度融合,智能座舱助手 AI Eva 已完成 DeepSeek R1 大模型集成并上线,上线后 AI Eva 进化出深度思考能力,为用户提供更全面精准的答案反馈。东风汽车研发总院完成了 DeepSeek 全系列大语言模型的接入工作,并将陆续搭载应用于东风奕派、东风风神、东风纳米等自主品牌车型,实现了更自然的语音交互、更智能的场景理解和更快速的功能迭代。DeepSeek 在汽车领域的应用,为智能座舱带来了更强大的交互能力和智能化体验,推动了汽车行业向智能化、网联化方向发展。
未来展望:机遇与挑战并存

随着人工智能技术的不断发展,DeepSeek 迎来了前所未有的机遇。从技术创新的角度来看,随着人工智能技术的飞速发展,新的算法、架构和应用场景不断涌现,为 DeepSeek 提供了广阔的创新空间。凭借其在模型性能和技术架构上的优势,DeepSeek 有望在自然语言处理、计算机视觉、语音识别等多个领域实现技术突破,进一步提升其在人工智能领域的竞争力。
在市场竞争方面,虽然人工智能市场竞争激烈,但 DeepSeek 以其出色的性能和亲民的价格,已经在全球范围内吸引了大量用户和合作伙伴。随着市场对人工智能技术的需求不断增长,DeepSeek 有望通过不断优化产品和服务,进一步扩大市场份额,与其他竞争对手展开有力角逐。
随着人工智能技术在各行业的应用不断深化,DeepSeek 的应用场景将更加广泛。无论是金融、医疗、教育等传统行业,还是新兴的智能硬件、物联网等领域,都对人工智能技术有着强烈的需求。DeepSeek 可以通过与各行业的深度合作,为用户提供更加个性化、智能化的解决方案,推动各行业的数字化转型和升级。
然而,DeepSeek 也面临着诸多挑战。在技术持续创新方面,虽然 DeepSeek 已经取得了一定的技术突破,但人工智能技术发展迅速,新的技术和模型不断涌现。DeepSeek 需要不断加大研发投入,保持技术创新的动力,以应对不断变化的市场需求和技术挑战。
市场竞争的压力也不容小觑。除了来自国内外其他人工智能企业的竞争,DeepSeek 还需要应对传统科技巨头在人工智能领域的布局和竞争。这些企业通常拥有雄厚的资金实力、丰富的技术积累和广泛的市场渠道,给 DeepSeek 带来了巨大的竞争压力。
数据隐私和安全问题也是 DeepSeek 需要面对的重要挑战。随着人工智能技术的广泛应用,数据隐私和安全问题日益受到关注。DeepSeek 在收集、存储和使用用户数据的过程中,需要严格遵守相关法律法规,加强数据安全保护,防止数据泄露和滥用,以保护用户的隐私和权益。
为了应对这些挑战,DeepSeek 需要采取一系列措施。在技术创新方面,加大研发投入,吸引和培养优秀的人工智能人才,加强与高校、科研机构的合作,共同推动技术创新和发展。在市场竞争方面,加强品牌建设,提升产品和服务质量,优化用户体验,通过差异化竞争策略,提高市场竞争力。在数据隐私和安全方面,建立健全的数据安全管理体系,加强数据加密、访问控制等技术手段,确保数据的安全和隐私。
展望未来,DeepSeek 有望在人工智能领域继续发挥重要作用,为推动全球人工智能技术的发展和应用做出更大的贡献。我们期待着 DeepSeek 能够不断创新,突破技术瓶颈,在机遇与挑战并存的发展道路上,实现更加辉煌的成就。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...

